


















每个尝试将旧系统数据迁移到 Jira 的工程师,都经历过这样的魔幻时刻:官方文档里薄薄一页《JSON 数据导入指南》,与现实中8.5万条数据、上百个自定义字段的复杂工程形成鲜明对比。这就像拿着景区导览图去攀登珠峰——方向没错,但生存指南全得自己摸索。
一、迁移前必须知道的三个真相
1.文档只是拼图的第一块:
就像宜家说明书不会教你怎么布线,官方指南也只会向你展示基础框架,真正的技术细节往往藏在字段 ID 映射、数据关系重建里。
2.失败是迁移的常态:
当一次性导入3500条数据测试时,可能会因一个特殊符号导致整批失败,这正是分批次操作的价值所在。
3.迁移≠搬运:
数据迁移是一个繁琐而庞杂的工程,对迁移速度、迁移质量、系统性能、兼容性、储存空间等都有要求,就像把图书馆藏书重新分类上架——需要建立新的编目规则。
二、手把手六步迁移法
STEP 1 搭积木:准备基础元件
- 先建好所有用户账号(就像先给新大楼分配门禁卡)。
- 创建自定义字段模板(提前规划好物品存放区域)。
- 小技巧:用 API 实时获取字段 ID,避免”字段幽灵”(显示不存在字段)。
STEP 2 化整为零:数据分块处理
- 每批处理3000-3500条数据,既规避JSON文件体积限制,又降低单次失败造成的回滚成本(相当于快递纸箱的合理承重)。
- 保留5%的”空白批次”用于补漏(就像搬家时预留应急箱)。
STEP 3 新旧系统双轨并行
- 迁移期间保持双系统运行(如同疫情期间的线上线下融合办公)。
- 在原始数据中植入”面包屑”:把 Jira 新 ID 回写到旧系统(类似快递单号双向可查)。
STEP 4 编织关系网
- 先搬家具后接线:待主体数据落位后,分阶段处理事项关联、附件及第三方系统(如 Salesforce)集成。
- 用正则表达式批量更新评论链接,确保知识资产的连续性(像智能替换文档中的旧电话号码)。
STEP 5 收尾的艺术
- 附件迁移用第三方工具(如同请专业搬家公司处理钢琴)。
- 在 FME 工具中保留完整工作流,形成可追溯的数据管道(制作属于自己的搬迁手册)。
STEP 6 验收清单
- 所有用户能正常登录
- 历史评论链接自动跳转
- 报表数据与源系统一致(加入可视化检查项提升实操性)
三、实战淬炼的三大迁移原则
1.元数据先行:先导入数据再建字段,容易导致部分数据变成”无家可归”的幽灵条目。自定义字段创建必须早于事项导入,通过 API 实时获取字段 ID 破解”字段幽灵”难题。
2.异步解耦思维:将用户体系构建、事项迁移、关系建立拆分为独立阶段,采用消息队列控制执行顺序。比如用 Python 脚本自动拆分大文件,比手动操作效率提升20倍。
3.容错设计准则:在 JSON 转换层预设数据清洗规则,自动过滤非法字符与格式错误。
4.重视迁移日志:记录每个批次的成功/失败详情,后期排查效率可提升80%。
四、Atlassian 迁移指南
当越来越多的团队在开源工具迁移中耗费数月精力,ONES 推出了更高效、安全、稳定的数据迁移解决方案,能够帮助团队将 Jira 和 Confluence 中的数据平滑迁移至新的研发管理平台,单个客户最大迁移数据体量可达 9.5T,Jira 和 Confluence 正式迁移成功率达100%。
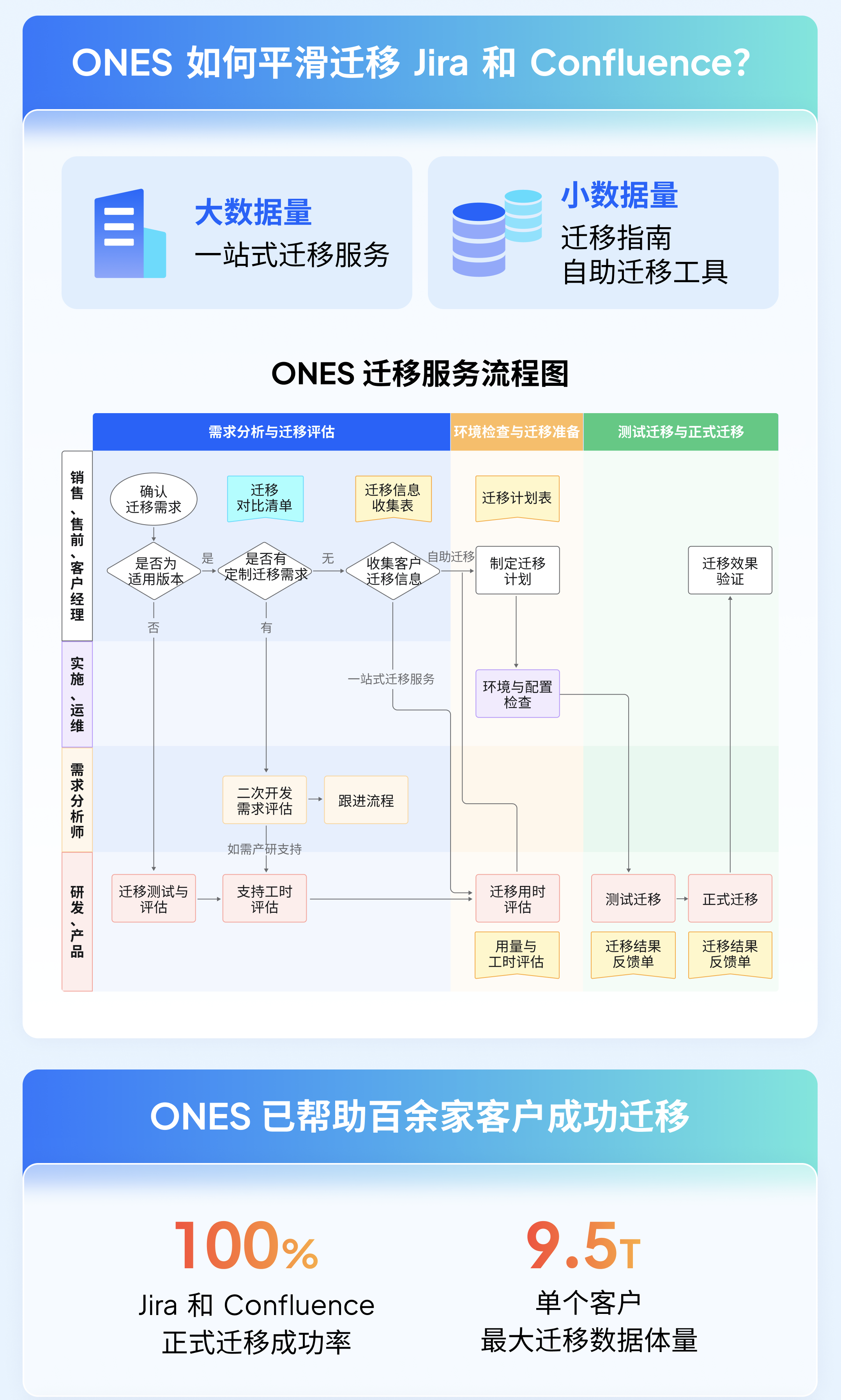
如果您也在寻找一款自主可控、适配信创的研发管理软件,关心 Jira & Confluence 迁移问题,可点击下方链接免费获取《企业级研发管理系统迁移指南》,希望这份指南能够帮助您评估和选择最适合您团队的迁移方式。
>>> 免费获取《企业级研发管理系统迁移指南》:https://ones.cn/migration/guide
阅读指南还可获取:
Jira 和 ONES Project 功能对比表
Confluence 和 ONES Wiki 功能对比表
从 Jira 到 ONES Project 的数据迁移效果图
从 Confluence 到 ONES Wiki 的数据迁移效果图


