


















在数字化转型的深水区,系统架构的稳定性与扩展性已成为企业的生命线。面对每秒百万级请求的电商大促、毫秒级响应的金融交易、以及海量数据处理的智能推荐,如何设计一个既能抗住洪峰(高并发),又能永不停摆(高可用)的系统架构,是每一位架构师面临的终极挑战。
本文将结合2026年的最新技术趋势,从核心原则、分层设计、关键组件到容灾演练,为您拆解一套生产级的高可用高并发架构蓝图,并重点介绍5款企业级研发管理平台:ONES、Jira、Confluence、GitLab、Jenkins。
一、核心设计原则:架构师的六大基石
在动手画图之前,必须确立六大核心原则,它们是衡量架构优劣的标尺:
- 冗余(Redundancy):任何单点都必须有备份。没有单点故障(SPOF)是高可用的基石。
- 解耦(Decoupling):模块间通过消息队列或API网关交互,避免”牵一发而动全身”。
- 伸缩(Scalability):支持水平扩展(Scale-out),通过增加机器线性提升处理能力,而非依赖升级单机硬件(Scale-up)。
- 失效转移(Failover):故障发生时,系统能自动切换到备用节点,用户无感知。
- 限流降级(Throttling & Degradation):在极端流量下,保核心业务,弃非核心功能,防止系统雪崩。
- 可观测性(Observability):全链路监控、日志、追踪,让系统内部状态透明化。
二、总体架构蓝图:分层防御体系
一个成熟的高并发架构通常采用分层架构,每一层都承担特定的防御和分发职责。
1. 接入层:流量的”第一道闸门”
- CDN加速:将静态资源(图片、CSS、JS、视频)推送到离用户最近的边缘节点,拦截80%以上的静态请求,大幅降低源站压力。
- 全局负载均衡(GSLB/DNS):根据用户地理位置,将流量调度到最近的健康数据中心(Multi-Region)。
- LVS/F5 + Nginx:四层负载均衡处理TCP连接,七层负载均衡(Nginx/Envoy)处理HTTP路由、SSL卸载和初步的IP黑名单过滤。
2. 网关层:系统的”智能路由器”
所有微服务请求必须经过网关(如 Spring Cloud Gateway, Kong, APISIX)。核心功能包括:
- 认证鉴权:统一校验Token,避免后端重复开发。
- 限流熔断:基于令牌桶或漏桶算法,限制单用户、单IP或单接口的QPS。
- 灰度发布:根据Header或Cookie将特定流量导入新版本服务。
- 协议转换:将外部HTTP/HTTPS请求转换为内部高效的RPC协议(如gRPC, Dubbo)。
3. 服务层:无状态的”计算工厂”
- 微服务化:将单体应用拆分为细粒度的服务(用户、订单、支付等),独立部署、独立扩展。
- 无状态设计:服务实例不保存会话状态(Session存Redis),确保任意实例宕机不影响业务,方便弹性伸缩(K8s HPA)。
- 异步解耦:非核心逻辑(如发短信、积分变更、日志记录)通过消息队列(Kafka, RocketMQ)异步处理,削峰填谷。
4. 数据层:一致性与性能的”平衡术”
多级缓存:
- 本地缓存(Caffeine/Guava):抗热点Key,毫秒级响应。
- 分布式缓存(Redis Cluster):承载大部分读请求,需防范穿透、击穿、雪崩。
数据库架构:
- 读写分离:主库写,从库读,通过中间件(ShardingSphere, MyCat)自动路由。
- 分库分表:当单表数据量超过千万级,按用户ID或时间进行水平拆分。
- NewSQL/TiDB:引入兼容MySQL协议的分布式数据库,自动处理分片和一致性。
- 异构存储:搜索用Elasticsearch,时序数据用InfluxDB,图关系用Neo4j,专库专用。
三、高并发核心策略:如何抗住百万QPS?
1. 缓存为王(Cache is King)
策略:能缓存的绝不查库。进阶采用 Cache Aside Pattern(旁路缓存),先读缓存,miss后读库并回写。对于极热数据,采用逻辑过期或永不过期+后台刷新。2026年趋势是利用AI预测预加载热点数据到缓存,实现”零延迟”命中。
2. 异步削峰(Asynchronous Peak Shaving)
场景:秒杀、下单、直播点赞。做法:请求进入消息队列后立即返回”排队中”,后端消费者按数据库承受能力匀速消费。优势:将瞬时流量洪峰拉平为稳定水流,保护数据库不被打死。
3. 池化与复用(Pooling)
- 连接池:数据库连接池(HikariCP)、Redis连接池、HTTP客户端连接池必须合理配置,避免频繁创建销毁连接的开销。
- 线程池:根据IO密集型或CPU密集型任务,定制隔离的线程池,防止某个慢接口拖死整个服务。
4. 动静分离与边缘计算
将动态计算逻辑尽可能下沉到边缘节点(Edge Computing),利用Serverless函数在靠近用户的地方处理简单逻辑,减少回源流量。
四、高可用核心策略:如何做到99.999%?
1. 消除单点故障(No SPOF)
- 集群部署:所有组件(网关、服务、缓存、DB、MQ)必须是集群模式,至少3节点(防脑裂)。
- 多活架构:
- 同城双活:两个机房同时提供服务,流量按比例分配。
- 异地多活:跨城市部署,单元化架构(Unitization),用户流量按单元封闭在特定区域,灾难时一键切换。
2. 熔断、降级与限流(The Triad of Resilience)
- 熔断(Circuit Breaking):当下游服务错误率超过阈值(如50%),快速失败,不再调用,防止级联故障。
- 降级(Degradation):系统过载时,关闭非核心功能(如推荐、评论、积分),保留核心链路(如下单、支付)。
- 限流(Rate Limiting):在网关和服务层设置QPS上限,超出部分直接拒绝或排队。
工具:Alibaba Sentinel, Resilience4j, Istio。
3. 超时与重试机制
- 超时控制:所有远程调用(RPC, HTTP, DB)必须设置合理的超时时间,避免线程长期阻塞。
- 智能重试:仅对幂等且非超时类错误(如网络抖动)进行有限次数的指数退避重试。严禁对写操作盲目重试。
4. 数据一致性保障
- 最终一致性:在分布式事务中,优先保证可用性,通过本地消息表、RocketMQ事务消息或TCC/Saga模式实现最终一致性。
- 对账补偿:建立T+1或实时的对账系统,自动发现并修复数据不一致。
五、可观测性与自动化运维:看见不可见
没有监控的系统就是在”裸奔”。
三大支柱
- Metrics(指标):Prometheus + Grafana,监控QPS、RT、错误率、CPU、内存。
- Logging(日志):ELK Stack (Elasticsearch, Logstash, Kibana) 或 Loki,集中收集和分析日志。
- Tracing(链路追踪):SkyWalking, Jaeger, OpenTelemetry,追踪一次请求在所有微服务间的流转,快速定位瓶颈。
混沌工程(Chaos Engineering)
主动在生产环境注入故障(如随机杀Pod、模拟网络延迟、断开数据库连接),验证系统的自愈能力。工具:ChaosBlade, Chaos Mesh。
自动化扩缩容
基于K8s HPA(Horizontal Pod Autoscaler),根据CPU/内存或自定义指标(如QPS)自动增减服务实例。
六、企业级研发管理平台选型:5款核心工具解析
1. ONES:一体化企业级研发管理平台
ONES 是企业级研发管理平台,核心优势在于一体化覆盖项目管理、需求管理、知识库、测试管理、流水线与代码管理,减少工具割裂。面向中大型组织,支持复杂流程配置、权限模型与跨团队协作治理。强调研发效能度量,支持以数据驱动改进交付质量与效率。
适用场景:中大型企业、多团队协同、需要端到端研发效能度量的组织。
2. Jira:敏捷项目管理的事实标准
Atlassian 旗下的 Jira 在敏捷开发领域拥有广泛的生态积累。其灵活的 Issue 类型配置、工作流自定义以及与 Confluence、Bitbucket 的深度集成,使其成为许多技术团队的首选。Jira 的优势在于成熟的插件市场和丰富的敏捷报表(燃尽图、速度图),适合已经建立敏捷实践且需要精细化迭代管理的团队。
适用场景:敏捷转型成熟、需要复杂工作流定制、已有 Atlassian 生态投入的团队。
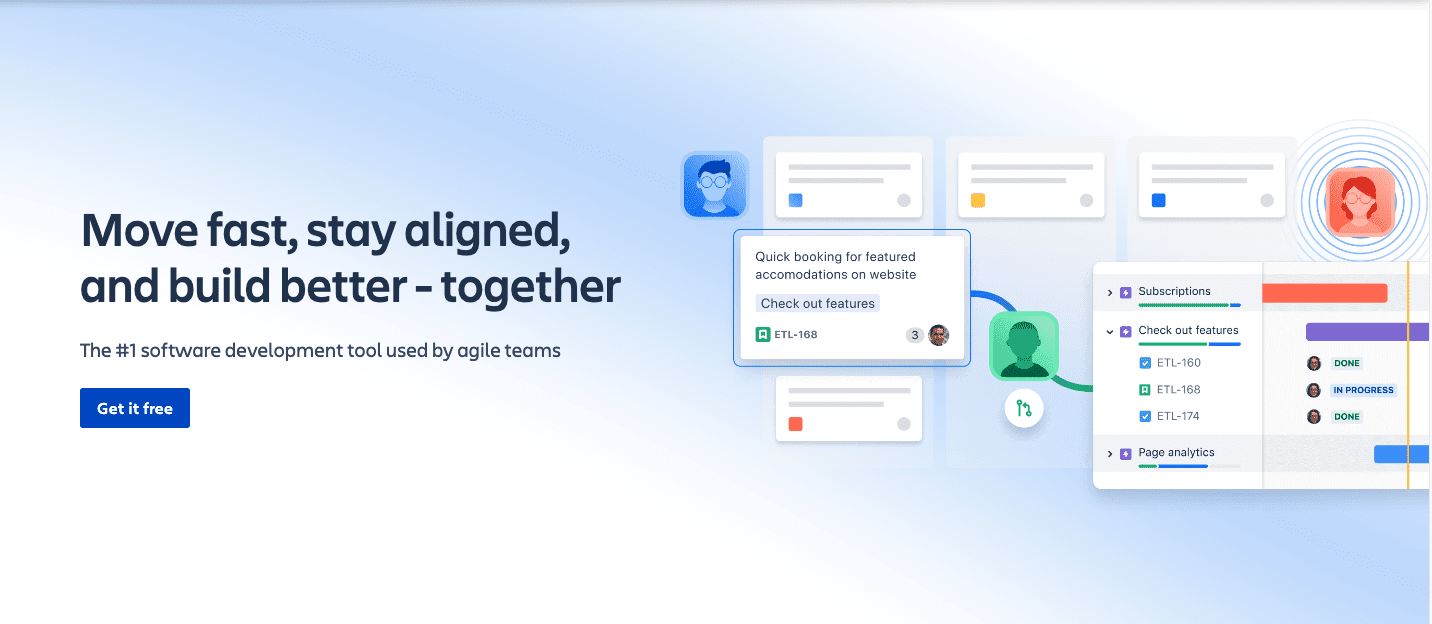
3. Confluence:知识协同与文档中枢
同样来自 Atlassian,Confluence 专注于企业知识库构建与技术文档协作。其页面树结构、模板库、实时协同编辑功能,配合与 Jira 的双向关联,形成了”需求-文档-代码”的完整链路。对于需要维护大规模技术文档、API 文档或产品手册的组织,Confluence 提供了结构化的沉淀方案。
适用场景:技术文档密集型团队、需要知识沉淀与复用的研发组织。
4. GitLab:DevOps 一体化代码平台
GitLab 从代码托管出发,逐步扩展至 CI/CD、安全扫描、容器镜像仓库等完整 DevOps 能力。其单一代码库即可触发流水线、执行自动化测试、生成安全报告的特性,降低了工具链集成的复杂度。GitLab 的 self-hosted 版本也为有数据主权要求的企业提供了部署灵活性。
适用场景:重视 CI/CD 自动化、需要代码级安全扫描、偏好单一平台整合的团队。
5. Jenkins:开源自动化服务器的持续价值
作为老牌开源 CI 工具,Jenkins 凭借近乎无限的插件生态和脚本灵活性,仍在自动化构建与部署领域占据重要位置。虽然其界面与现代工具相比略显陈旧,但对于需要高度定制化流水线、复杂编排逻辑或与遗留系统集成的场景,Jenkins 的可编程性难以替代。
适用场景:复杂流水线定制、遗留系统集成、拥有专职运维开发团队的企业。
七、架构演进路线图
| 阶段 | 特征 | 关键技术 | 适用规模 |
|---|---|---|---|
| L1: 单体架构 | 所有功能在一个WAR包,单库单表 | Spring Boot, MySQL | 日活 < 1万 |
| L2: 垂直拆分 | 按业务模块拆分单体,独立部署 | Dubbo, Redis, 主从DB | 日活 1万 – 10万 |
| L3: 微服务化 | 细粒度服务,治理中心,读写分离 | Spring Cloud, K8s, MQ, 分库分表 | 日活 10万 – 1000万 |
| L4: 云原生/多活 | 容器化,Service Mesh,异地多活,Serverless | Istio, TiDB, Multi-Region, AI Ops | 日活 > 1000万 |
八、结语:架构是演进而非设计
高可用高并发架构不是一蹴而就的”完美作品”,而是一个持续演进、不断妥协的过程。
- 不要过度设计:在业务初期,简单的单体+读写分离可能比复杂的微服务更高效。
- 敬畏线上环境:任何变更都要经过严格的测试、灰度发布。
- 人是核心:再好的架构也离不开规范的流程、敏锐的监控和训练有素的团队。
在2026年,随着AI辅助编码、智能运维(AIOps)和Serverless的普及,架构师的重心将从”堆砌组件”转向”编排智能”与”治理复杂度”。唯有如此,方能构建出真正坚不可摧的数字堡垒。
常见问题(FAQ)
Q1:中小企业是否需要一开始就采用微服务架构?
不建议。业务初期团队规模小、迭代速度快,单体架构配合良好的代码分层足以支撑。微服务带来的运维复杂度(服务发现、分布式追踪、多环境管理)需要相应的人力和基础设施投入。建议日活突破10万或团队超过50人时,再评估拆分必要性。
Q2:如何在高可用与数据一致性之间做权衡?
遵循 CAP 定理的指导,根据业务场景选择策略。金融支付等强一致性场景采用 CP 方案(如 Raft/Paxos 共识算法);电商订单、社交 feed 等可用性优先场景采用 AP 方案,通过最终一致性保障(消息队列、对账补偿)实现软状态收敛。
Q3:研发管理平台选型最应关注哪些因素?
首要评估组织规模与协作模式:中小团队侧重易用性与快速上手,大型组织关注权限治理、流程自定义与数据贯通能力。其次考察与现有工具链的集成成本,以及供应商的服务响应与数据安全合规资质。
