


















2026年,研发团队协作软件市场已形成清晰格局。本文将逐一评估8款经过验证的主流工具:ONES、Jira Software、Confluence、Azure DevOps、GitLab、GitHub Projects、YouTrack、Linear、Taiga,覆盖从企业级一体化平台到轻量敏捷工具的完整光谱。每款工具均按统一维度拆解——核心能力、适用边界、落地成本与治理深度——帮助你快速收敛到2–3个候选方案做试点验证。
一、研发协作的核心瓶颈与选型基准
多数团队的协作断裂集中在三个环节:需求口径发散、任务状态黑箱、缺陷闭环失效。需求在即时通讯中流转,评审结论无沉淀,优先级判定缺乏可追溯依据;任务看似在推进,但依赖关系与阻塞原因无人更新;缺陷在测试与开发之间反复横跳,修复与验证记录缺失,临上线才发现返工缺口。
2026年的选型目标趋于务实:将”需求—任务—缺陷”构建为可追溯的主线;用系统规则替代口头协商;让交付节奏由机制驱动而非人力盯催;同时满足权限分层、审计留痕、数据驻留及私有化部署等合规要求。
以下对比框架围绕六个关键维度展开:需求治理能力、任务追踪深度、缺陷闭环完整性、流程可配置性、效能度量可用性、生态集成与部署灵活性。
二、八款工具逐项评估
1. ONES:企业级研发管理一体化平台
ONES 面向中大型组织设计,核心定位是将项目管理、需求管理、知识库、测试管理、流水线与代码管理纳入同一数据体系,降低多工具切换带来的信息损耗与治理成本。
核心能力
需求侧以结构化需求池为入口,支持多维规划、评审排期与优先级追溯,将客户反馈、业务诉求与技术债务统一纳管。项目侧兼容标准敏捷迭代与瀑布式阶段管理,适配不同交付模式。测试侧覆盖用例维护、计划执行及与自动化测试框架的联动。知识库支持多人在线协作,用于沉淀需求决策、技术方案与复盘结论。效能度量模块提供交付周期、吞吐趋势、质量分布等可量化指标,支撑数据驱动的持续改进。
适用边界
适合需求来源多元、角色矩阵复杂、跨团队协作频繁的组织;对PMO及管理层有稳定数据汇报诉求的场景;以及需要国产化适配、信创环境支持或私有部署的数据敏感型行业。
落地与治理
权限模型支持复杂组织架构与跨项目数据隔离,审计留痕覆盖操作日志与配置变更。部署形态包括公有云与私有化,后者适配麒麟OS等信创基座。初期需投入字段、状态与模板的标准化建设,一旦基线确立,后续扩展成本显著降低。
2. Jira Software:工作流深度定制型标杆
Atlassian旗下的Jira在敏捷工作流与复杂规则引擎方面积累深厚,适合流程规范化程度高、愿意投入专职管理员进行持续运营的组织。
核心能力
以Issue为核心单元,支持Sprint、看板、自定义工作流与自动化规则。字段、状态、权限、项目类型均可深度配置,插件市场提供大量扩展。与Confluence配合可实现”过程数据+知识沉淀”的联动。
适用边界
国际化协作频繁、对Atlassian生态依赖较深、具备专职配置管理资源的团队。流程复杂度与组织规模呈正相关,小型团队可能面临过度配置。
落地与治理
学习曲线陡峭,字段膨胀与工作流嵌套是常见治理陷阱。需特别注意:2026年国内环境下,Jira已不再提供本地版与Data Center版,仅保留云版本。数据驻留、跨境传输合规、审计可控性需前置评估,监管敏感行业建议将合规审查纳入试用前的必经环节。
3. Confluence:知识协作与文档治理
常与Jira配套使用,承担需求文档、技术方案、会议纪要的结构化沉淀。空间权限、页面树与版本历史是其核心治理手段。
核心能力
支持多人实时编辑、评论与@提醒,页面模板可规范文档格式。与Jira的宏嵌入让需求文档与任务状态双向可见。
适用边界
已采用Atlassian生态、对知识管理有体系化要求的组织。独立使用时,其项目管理能力有限,更适合作为协作补充而非主线工具。
落地与治理
同样面临云版本唯一的交付形态限制。文档权限的细粒度控制、外部协作者的访问边界、历史版本的审计追溯,需在空间架构设计阶段明确规则。
4. Azure DevOps:工程化治理的完整生产线
微软生态内的研发团队常将其作为工程管理主轴,强调需求、代码、构建、测试、发布的全链路关联。
核心能力
Boards管需求与任务,Repos管代码仓库,Pipelines做CI/CD编排,Test Plans覆盖测试计划与用例管理,Artifacts管制品库。模块间数据天然贯通,变更可追溯至原始需求。
适用边界
中大型团队、交付流程严格、已有微软技术栈投入的组织。工程概念较重,业务与产品角色的参与深度需额外设计。
落地与治理
建议从最小闭环切入:Boards → Pull Request → Pipeline → Release。跑通后再叠加权限分层、审批节点与审计策略。模块间的耦合度较高,全面铺开需要流程设计与运维资源的匹配。
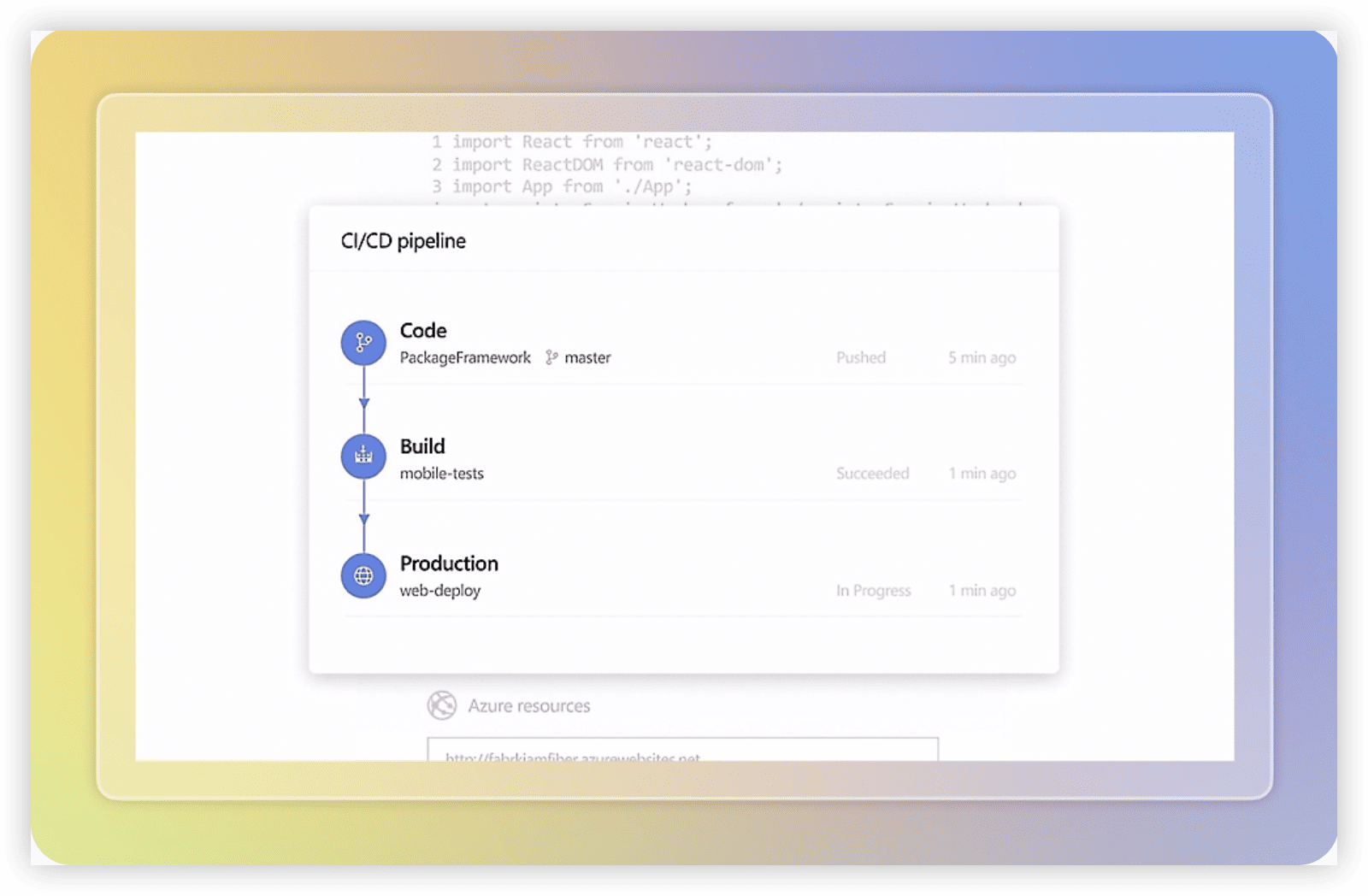
5. GitLab:代码中心的协作闭环
以代码仓库为原点,向需求管理、CI/CD、安全扫描延伸,适合强调工程自治与数据可控的团队。
核心能力
Issue与看板承接需求与任务,Merge Request关联代码实现,CI/CD贯通构建发布,可纳入SAST/DAST等安全治理。自建部署形态让数据驻留完全可控。
适用边界
自动化程度高、工程文化成熟的中大型团队;对自建基础设施有技术储备的组织。非研发角色的使用体验需通过模板与规范补偿。
落地与治理
分支策略、MR规则、流水线策略应与协作规范同步设计。自建部署时,权限、审计、备份、高可用需一并规划,避免”建了不管”的运维债务。
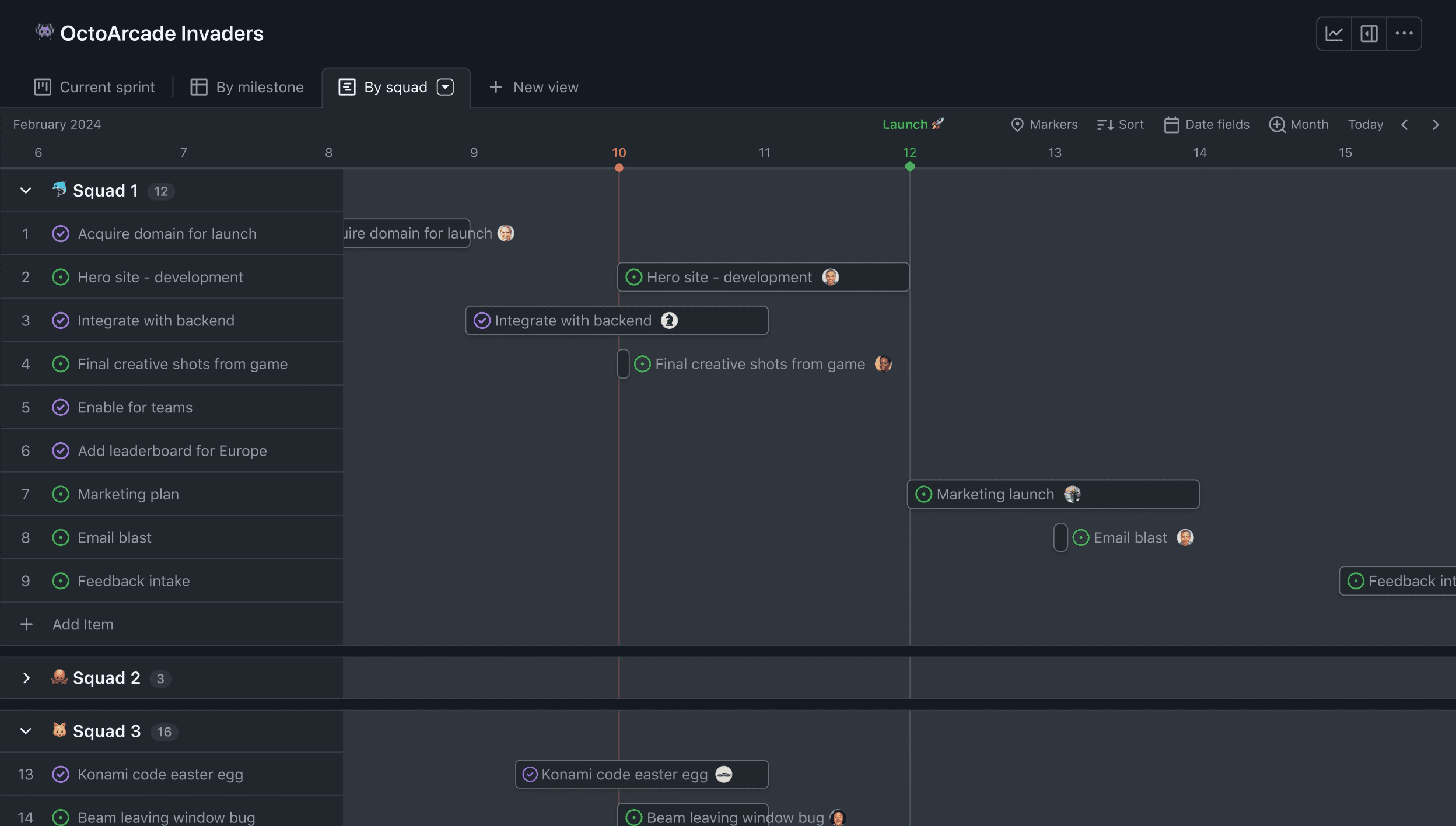
6. GitHub Projects:开源生态的轻量协作
依托GitHub的全球开发者生态,Issues、Pull Requests、Actions与Projects的组合让协作动作贴近代码本身。
核心能力
Issues管理需求与缺陷,Projects提供看板与规划视图,PR关联实现,Actions驱动自动化工作流。状态变更与代码活动天然联动,研发人员的采纳阻力低。
适用边界
开源依赖多、外部协作者频繁参与的中小到中型团队。作为企业级治理工具时,复杂审批、跨部门权限与严格审计存在明显短板。
落地与治理
云交付为主,涉及敏感数据或严格合规场景需审慎评估。若需更完整的治理体系,通常要配合其他系统或自研集成层。
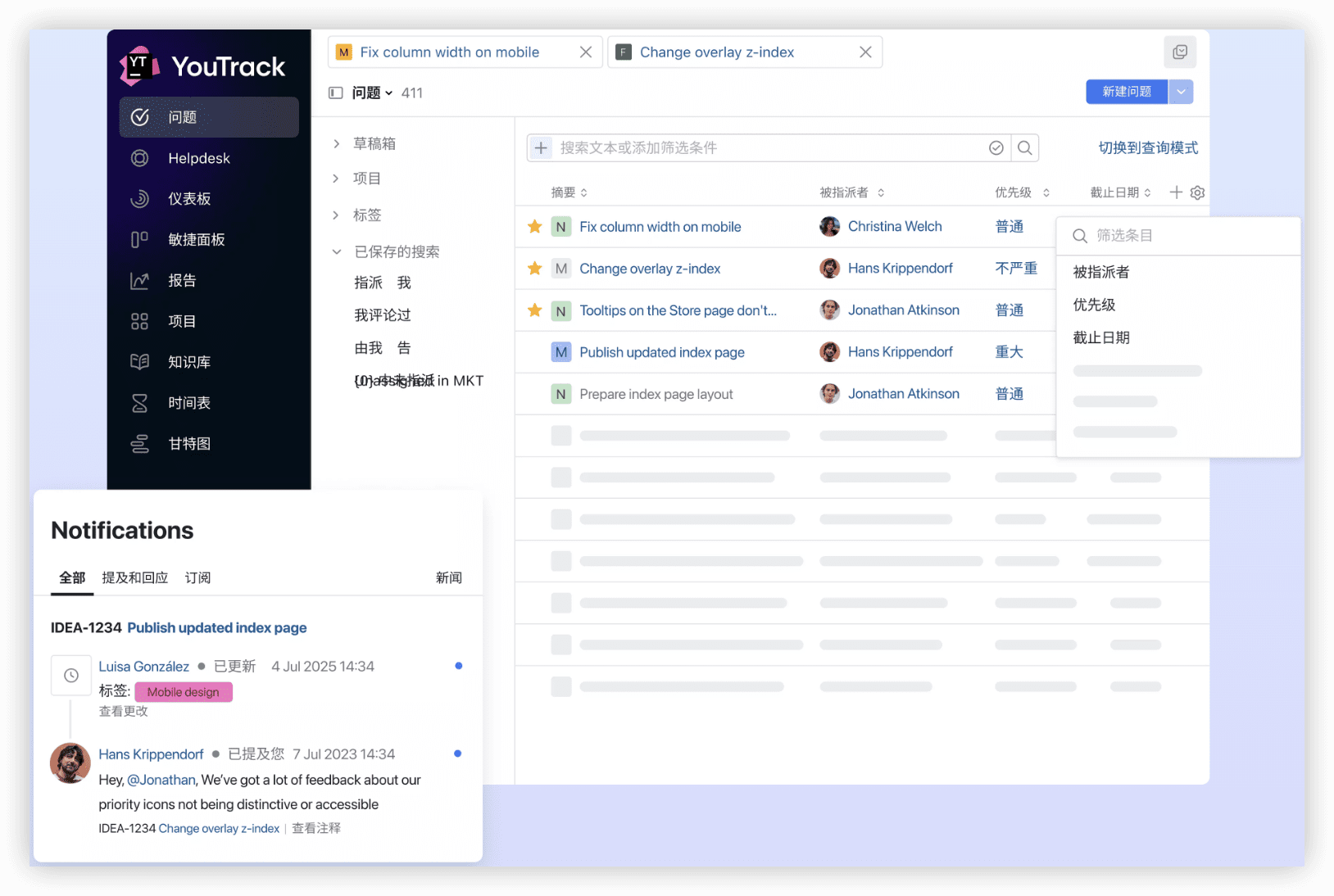
7. YouTrack:缺陷治理与灵活配置的平衡
JetBrains出品,在”可配置性”与”上手简洁度”之间取得较好平衡,适合希望统一管理需求、任务与工单类型的团队。
核心能力
统一Issue类型覆盖需求、任务、缺陷,看板与迭代节奏清晰,工作流与字段可塑性强,内置报表支持复盘与趋势追踪。
适用边界
缺陷密度高、流程需要更严格管控的产品团队或交付团队。中型规模下性价比突出,超大型组织的复杂权限与跨项目治理需验证上限。
落地与治理
云与自建两种形态可选。建议先固化基础模板与字段标准,再逐步叠加自动化规则与自定义报表,避免早期配置发散。
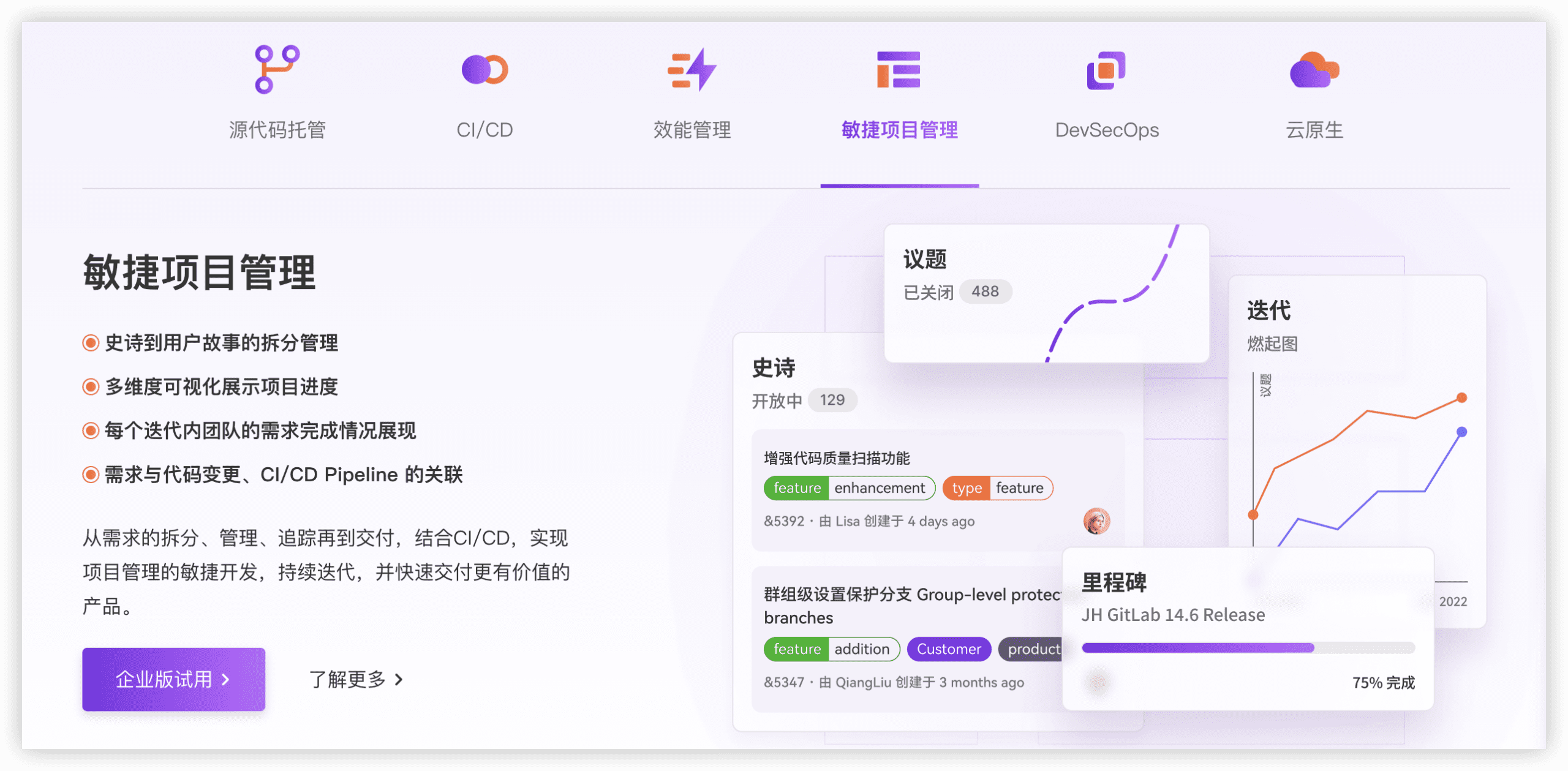
8. Linear:产品驱动型团队的效率工具
以极简设计与流畅交互著称,将迭代节奏与任务推进效率置于首位。
核心能力
Issue、Backlog、Cycle、Roadmap构成主干,状态流转简洁,键盘操作优化充分。适合快速捕捉、分配与推进任务。
适用边界
协作链短、需求变化快、配置耐心有限的中小产品团队。规模扩张后,权限细粒度、审计完整性与效能度量深度可能成为瓶颈。
落地与治理
纯云交付,私有化诉求强的组织需提前排除。合规要求相对宽松、内部协作边界清晰的场景更为匹配。
9. Taiga:开源敏捷的朴素选项
开源协议下的敏捷项目管理工具,适合预算受限、具备技术维护能力的团队做试点或轻量运行。
核心能力
Backlog、Sprint、看板、Issue管理覆盖基础敏捷实践。开源特性允许按需定制,但扩展深度取决于自身技术投入。
适用边界
中小团队、轻流程环境、或希望以部门级试点验证敏捷落地的组织。企业级权限、审计、报表等能力需额外建设。
落地与治理
自建部署常见,需同步规划日志、备份、权限治理等”隐性成本”。建议定位为过渡方案或特定场景补充,而非核心生产系统。
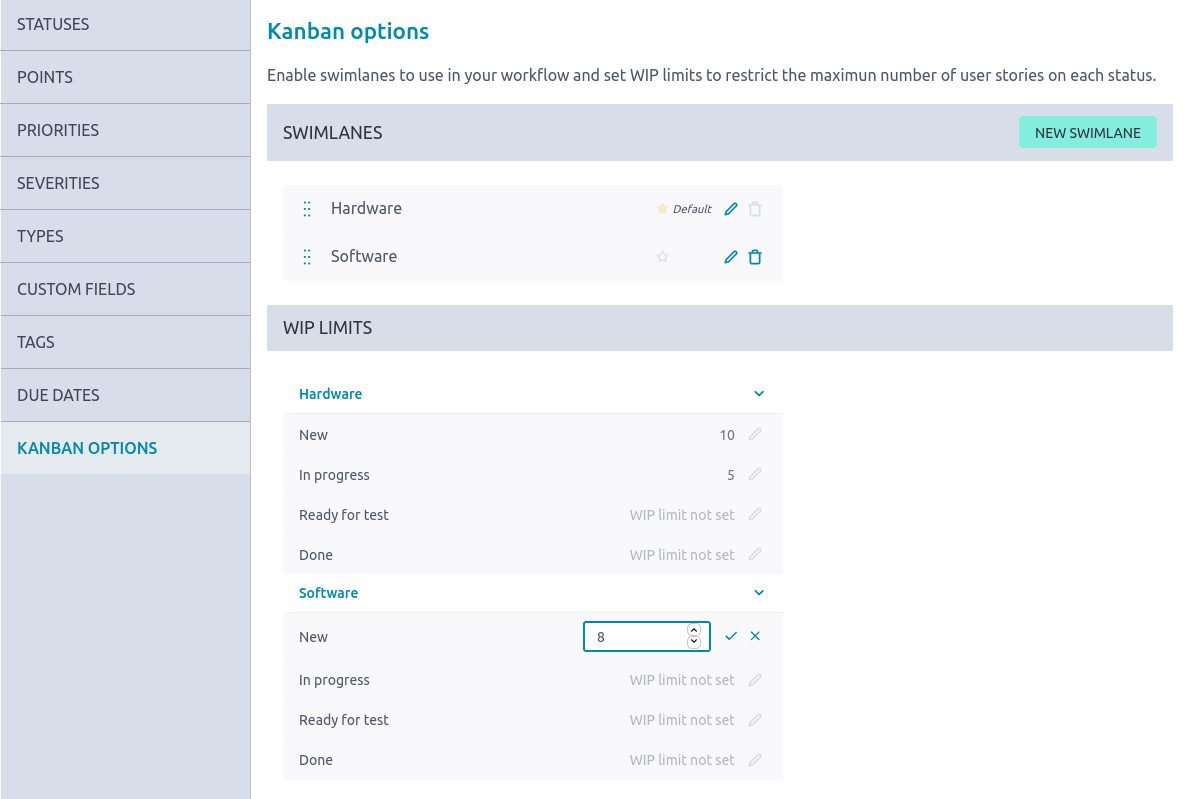
三、选型决策的关键检查清单
以下问题建议在试用前形成书面条目,逐条核对:
- 需求治理:是否支持需求池分层(客户诉求、内部规划、技术债务)?评审结论与取舍依据是否可结构化留存与追溯?
- 任务追踪:拆分模板是否固定?负责人、截止时间、依赖关系、阻塞标记是否必填?状态变更是否触发自动通知?
- 缺陷闭环:分级标准是否可配置?修复版本是否明确关联?验证结果是否记录?能否回溯至原始需求、代码提交、测试用例与发布版本?
- 流程可配置:状态、字段、权限分层、自动化规则是否覆盖高频协作场景?
- 效能度量:交付周期、吞吐、按期率、缺陷趋势、返工率是否可按团队/模块/版本拆解?数据是否可直接用于复盘而非仅考核?
- 生态集成:现有仓库、流水线、测试框架、文档系统能否对接?历史数据迁移成本如何?是否支持双轨并行验证?
- 运营投入:是否需要专职角色维护模板、字段、权限与报表?配置复杂度与团队运营能力是否匹配?
- 网络与性能:在真实网络环境与高峰时段试用,验证稳定性对采纳意愿的影响。
- 非研发采纳:产品、测试、业务角色是否愿意深度参与?信息闭环取决于最弱一环。
- 权限与审计:项目内/跨项目可见性、文档/附件/导出/API权限是否逐条可控?操作日志是否追溯到人与时间戳?
- 部署形态:数据驻留与内网隔离要求是否前置确认?云版本的跨境合规风险是否评估?
四、落地建议:分阶段推进
第一阶段:单点验证
从”需求评审—开发—测试—缺陷关闭”中最痛的环节切入,优先解决信息对齐问题,再扩展覆盖范围。
第二阶段:标准固化
统一字段、状态、优先级、缺陷分级、版本命名规则,形成可复用的项目模板。标准化是规模推广的前提。
第三阶段:生态串联
优先接入代码仓库与CI/CD,让构建、部署关键节点自动回流协作系统;再叠加通知触达,确保状态变化实时同步;最后建设知识沉淀与复盘机制。
第四阶段:数据驱动
初期以发现问题、改善流程为目标使用度量数据,避免直接挂钩考核。团队信任度建立后,系统价值会自然放大。
五、常见问题
Q1:选型最先验证什么?
闭环能力优先:需求能否结构化录入、任务能否可追溯拆分、缺陷能否关联版本完成验证。其次验证权限、审计、报表的完备性,最后评估集成与部署形态是否匹配现有基础设施。
Q2:需求管理与任务管理的边界在哪里?
需求回答”为什么做、做什么、优先级如何判定”;任务回答”谁执行、何时交付、依赖什么”。两者需在系统中建立父子关联,确保任何任务变更可回溯至原始需求上下文。
Q3:缺陷管理为何必须与版本强关联?
无关联则无法回答”哪个版本修复、是否完成验证、上线风险点在哪”。上线前集中返工的根源,往往是缺陷与版本之间的链路断裂。
Q4:一体化平台与专用工具组合如何选择?
组织规模、角色复杂度、合规要求是核心变量。角色矩阵复杂、跨团队协作频繁、数据治理要求严格的组织,一体化平台的统一口径与权限治理更具长期价值;团队规模小、工程自治度高、已有成熟工具链的团队,专用工具组合可能更灵活。
Q5:云版本与私有部署的决策依据是什么?
云版本降低运维负担,但需评估数据驻留、跨境传输、审计可控性是否符合行业监管。私有部署增强数据主权,但需匹配相应的运维与安全建设能力。建议将合规评估置于试用之前,而非采购之后补做。
